Sunday, February 15, 2004
Google Disallows "Anti" Ads
“Under the Anti policy, Scientology is allowed to promote its murderous cult, but its detractors are not allowed to point out that harm it causes. Royal Caribbean can promote its polluting cruises, but Oceana cannot discuss how they pollute. The President could promote his agenda, but the opposing party could not respond with its problems
These opposing viewpoints are not hate speech or offensive, they simply try to provide readers with all the facts. By only permitting promotion and never caution, Google does us all a disservice, and makes it seem like there is only one side to every issue. This is the antithesis of the democratic Web Google claims to support.”
– Aaron Swartz, Anti AdWords Strike Again (The Google Weblog), February 13, 2004
Gogole
It looks like Google... but it’s not. It’s spelled Gogole (and that’s not the Google-owned Gogole.com, but a spoof).
Adult Google Directory
Did you know that Google features the Adult section of the Open Directory? You cannot choose it directly from the main page but have to enter the URL manually: directory.google.com/Top/Adult/ – where no fetish is too obscure to be covered.
In other news Google is suspected to drop its DMOZ.org listings soon (some new-design screenshots don’t show the “Directory” tab).
Creating a Mobile News Portal for the Nokia 6600
With my new Nokia 6600 and its built-in browser, I can view the World Wide Web, and not just the awkwardly small WAP 1.0 portion. WAP 2.0, the newer implementation of the Wireless Application Protocol, replaced WML (the Wireless Markup Language) in favor of XHTML. As you may know, W3C (World Wide Web Consortium) has recently recommended that XHTML be used as the mark-up language for web pages.
This article was previously published in SymbianOne and mentioned in Slashdot. The only addition I have to make now: don't use Opera, don't use the Nokia browser, use the great Netfront Access. Simply the best Symbian-based browser out there. (Google works good on it, too!)
The Background
The original idea of HTML inventor Tim Berners-Lee was to have a device independent information channel. Web pages were intended to separate content (HTML, the Web's lingua franca), layout (CSS, Cascading StyleSheets) and functionality (JavaScript, a Netscape-invention now standardized as ECMAScript). Using this separation of content, layout and functionality Web pages should cover, not only the full-sized screen of the desktop PC, but also Braille-readers, print output, Text-to-Speech (TTS)... and mobile phones.
The Document Format
However, just using XHTML 1.0 Strict with a stylesheet for the medium "handheld" is not enough to target all mobile devices. The Series 60 browser requires you to include the XHTML Basic or XHTML Mobile Profile Doctype. Since my pages are XHTML 1.0 Strict already, I found it was not necessary to change the Doctype. Simply using the Basic DTD within an HTML comment (see Example 1) the browser could be tricked into interpreting my XHTML.
Example 1
<!DOCTYPE html
PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head>
<meta http-equiv="Content-Type" content="text/html; CHARSET=UTF-8" />
<title>Cross-Media</title>
<link rel="stylesheet"
href="default.css" type="text/css" media="handheld" />
<link rel="stylesheet"
href="default.css" type="text/css" media="screen" />
<link rel="stylesheet"
href="screen.css" type="text/css" media="screen" />
</head>
<body id="blog">
<!--
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML Basic 1.0//EN"
"http://www.w3.org/TR/xhtml-basic/xhtml-basic10.dtd">
-->
<h1>Cross-Media</h1>
<!-- ... -->
</body>
</html>The code in Example 1 is served as content-type "text/html" to also work in Internet Explorer, or other, older browsers which don't understand XML/XHTML (HTML4 and previous versions are based on SGML, while XHTML is based on XML – still, for XHTML 1.0 it's valid to serve the page as "text/html").
The Content
So now I can use HTML and stylesheets on my Nokia. I can use text colors, background colors, background images, borders, floating blocks. It all works fine; but where's the content?
I want recent news. Pictures are too much, as I will pay for traffic (that might be as much as 0,10 Euro per 30KB block with my German T-Mobile provider if I go over a monthly 5MB limit). But even without images, the endless navigation links or other "garbage text" is too much... slow, confusing, costly, and it may also crash the browser.
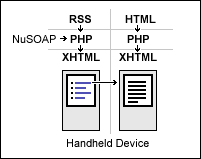
RSS is the solution. The "Really Simple Syndication" (or "RDF Site Summary"), based on the W3C XML standard, is a meta-file which gets straight to the point. Basically, it's a single file at a constant position telling Web automats: these are my recent headlines. This is their description. And here's the permanent link to the article. RSS is commonly used in personal Weblogs (Blogs) and indicated by a little orange "XML" button, but bigger news sites are also staring to provide RSS feeds.
There are different RSS wrappers available for different languages. I use PHP along with NuSOAP, both running on my Apache server. (You might also use Python, ASP, ASP.NET, JSP, or others.) I now choose some RSS news feeds, like "Yahoo! Top Stories". After reading them, I display a link list as XHTML.
<?
require_once '../magpierss/rss_fetch.inc';
$url = "http://rss.news.yahoo.com/rss/topstories"
$rss = fetch_rss($url);
$items = array_slice($rss->items, 0, $max_items);
echo "<h2>" . $rss->channel['title'] . "</h2>";
foreach ($items as $item)
{
$title = $item[title];
$url = $item[link];
$item_description = $item[description];
// ...
}
?>Now when the headline catches my interest and I follow the link, the tool will try to grab and deliver the content of the actual page by checking for text between two delimiters. These delimiters need to be adapted on a per-site basis (e.g. I might grab everything between the text of the headline and the string "Copyright by"). Next, I strip all tags, and include some simple structural tags (like "
" page breaks). Finally I end up with a fast-loading minimalist version of the original web page, ready to be viewed on my phone (I could make the URL public to be accessed by other people as well, but that might go against a site's copyright restriction).
Some RSS feeds also include the content of the blog post, so you don't need to convert the HTML using the delimiter hack. This approach is preferable as there is one problem with the "screen-scraping" technique: it might stop working if the grabbed page changes its HTML structure.
Conclusion
This seems like a whole lot of work just to browse the Web the way it was intended. Still I'm quite excited to see that it works at all within this limited display space. The more the Symbian OS and handheld browsers gain audience, the more important it will become for webmasters to change their pages to work cross-media. There might come a day when competition won't allow online publishers to think single-media.
Seven Deadly Search Engine Sins
Here are the seven deadly search engine sins. They will certainly make people run away. If not today, then tomorrow. And they are certainly annoying enough to hinder usability.

Pop-ups. Just don’t do it. If this month you could only choose one thing that’s annoying, this would be it. [Most prominent sinner: MSN Search.]
Unclear separation of advertisement and normal results. People don’t like webmasters to cash in with no advantage to them and the smell of trickery. [Most prominent sinner: AllTheWeb.]
Too many “sponsored results” or “related topics” on top, pushing normal results way down the page. Especially of the eBay kind (the fact they got the money to buy every word in a dictionary doesn’t mean their ads are relevant). It just wastes time and real screen estate. [Most prominent sinner: MSN Search.]
Cluttered front page. A search engine must have a strong focus on what it’s good at and present little more than its search box. Late-90s AltaVista desaster should be avoided. [Most prominent sinner: Lycos.]
Judging content. A search engine should not display result based on an editor’s opinion. No censorship or politicial judgment of any sort should be made. [Most prominent sinner: AOL Search.]
Forcing a language or country version. If I type dot-com, I don’t want to end up at dot-de in German. I might prefer international results. [Most prominent sinner: Google.]
Using redirects instead of straight links. This is nice to count clicks but depending on your connection it might steal your time. And it certainly irritates visited versus unvisited link colors. [Most prominent sinner: Yahoo.]
In a nut-shell, the message to search engine designers is: don’t do anything unless you’re told to.
Guestbook Spamming
February 16th will be the end of the SERPs competition to get your site listed on the number 1 spot in Google for “SERPs”. It started last month. Sam’s page climbed to the top spot, and when he deserted it, I took over his Blogspot account – which would make me the winner tomorrow. There are a whole lot of people participating in the competition using many different techniques. One of them, and currently the most successful, is guestbook spamming.
What is Guestbook spamming?
Guestbook spamming is when you get backlinks to your page via other people’s public guestbooks. These might display the URL itself as link-text, so it’s important to have the keyword inside the URL – true for e.g. serps.blogspot.com because Google used the dot as word-separator. The higher the guestbook’s PageRank, and the less links already on that page, the better your chance for making this strategy successful. (How do you find high-ranking guestbooks? Well, Google will show those first for certain creative search phrases!)
Then again, Google might one day figure out how Blog comment/ guestbook spamming is done and give the death penalty to over-optimized sites which mainly get “fake” backlinks. Getting rid of link-farmed top result pages would certainly make for a better Google.
Google Displaying Page Count
“I’ve gotten to thinking - what’s the use of having all those results? I mean, really, from a user interface point of view, the only information we gain from “Results 1 - 10 of about 3,950,000” is the rather attenuated sense that the search engine is, in fact, pretty darn thorough.”
--John Battelle’s, The Reshuffle Button (Searchblog), February 14, 2004
Result count is very important to me when searching. It can indicate a need to enter more search terms (if the result count is too high), or to cut down on terms (if the count is too low). Often you can drill down on the result by entering more terms until you hit a critical mass of say 100 pages.
E.g. you could start with “Citizen Kane” then go to “Citizen Kane Review” then over to “Citizen Kane Review Rosebud Meaning” to “Citizen Kane Review Rosebud Meaning Director Quote”. The hit count of the first search already is an indicator of how many pages on “Citizen Kane” are out there – if there’d be only a few pages on the movie, you’d have to settle down with the pages you are served, unspecific to your request as they may be.
So displaying this page count detail is absolutely crucial for more reasons than just this. (And you can write a lot of applications based on it, like Centuryshare.) Just like the URL display in a search result, you often can’t exactly explain why you need it, but would absolutely dislike a search engine which would cut this info.
But then again, I find the search time display pretty uninforming! Do I really care if it was one microsecond more or less? To me the only difference is between “I have to wait” and “The results are there instantly”. Google obviously falls into latter category.
>> More posts
Advertisement
This site unofficially covers Google™ and more with some rights reserved. Join our forum!