Tuesday, February 13, 2007
VTO, the German Google Book Search Killer?
By Mathias Schindler
When Google announced its “Google Print” project (now known as “Google Book Search”), it caused quite a stir within the traditional publishing industry and among physical book stores. Some of the reasons to worry were based on rumors and Google’s decision to have two single projects, the Library Project and the Publisher Partnership Program under one brand. Even if some of the publishers participated in the Publisher Program, they tried to stop Google from indexing books from libraries and to make them searchable.
In Summer of 2005, the “Börsenverein des Deutschen Buchhandels” (German publishers’ and book shops’ association) announced a project called “Volltextsuche Online” (VTO, “full text search online”) to counter the Google Book Search project. They also supported one lawsuit by the Wissenschaftliche Buchgesellschaft (WBG) against Google.
The lawsuit, which took place in summer 2006, asked the court of Hamburg to grant a preliminary injunction against Google (Inc. and Germany GmbH) to prohibit
- to scan books published by the WBG
- to provide access of these books to the public
During a hearing, the judge indicated that he does not see a legal basis for this injunction and in order to not lose before court, the WBG withdrew their motion.
Volltextsuche Online was first announced as a “decentralized” system and an interface for publishers to provide full text search of parts of their books to
- Search engines
- other “interested web providers”
- terminals in book shops
- a “book-affine search engine developed by the book publisher industry”
The status of the VTO system
The Börsenverein announced VTO to start in spring 2006. The start of VTO was later postponed to the book fair in fall 2006. A Powerpoint presentation [PPT] from last week says that an early system for uploading data will go online this week.
However, core parts of the system are still completely unknown. The original proposal of decentralized storage within the publishers servers turned out to be not practical, the idea was scrapped. The draft contract between VTO and the publishers reserves the right to VTO to store the data anywhere they like.
VTO is based on a software called “BookStore”, developed by a Holtzbrinck company MPS. In order to participate in VTO, a publisher has to list its book in the VLB (directory of in-stock books), it therefore has to have an ISBN. The annual fee is currently 17 Euro per year plus tax (yes, that’s correct: Book publishers have to pay to upload their data to VTO). However, the annual fee is suspended until March 31: Anyone who participates in VTO before that day can get one year free of charge.
Unlike Google Book Search, there is no way to just send the physical book to VTO, the publisher has to send in a prepared PDF file and several meta files. The specification of the meta files is currently in version 0.9 [PDF], it basically lacks any specific meta file information. VTO announced version 1.0 to be released in January. After sending two emails, the head of VTO said that version 1.0 will be released this week.
During the annual book fair in Frankfurt in 2006, VTO had a small demonstration of their BookStore installation. VTO claims that there is no way of saving or printing the pages of the book. When I spoke with VTO representatives, they acknowledged that this sentence is not meant literally but that they only prevent users (lobotomized users?) from saving the files by disabling the right mouse button or something. As of February 2007, VTO still claims that (rough translation):
Are internet users able to print the pages which are released for displaying?
Answer: No, this function has been disabled in the browser of the internet user at Volltextsuche-Online.
Are internet users able to print the pages which are released for displaying?
Answer: No, this function has also been disabled in the browser of the internet user at Volltextsuche-Online.
Today, I spoke with Katrin Neuberger who is working in the VTO team. She stated that the FAQ entries regarding saving and printing pages are correct and that no end user is able to save or print the pages. I specifically asked her whether this is not just referring to disabling the right mouse button and after a while, she said that she has to ask her superiors. She could not tell me how long it would take to get this answer.
Last weekend, VTO uploaded a presentation of this project which was given during a meeting in early February. The first version they uploaded was a 12 KB ppt file which was empty. After I pointed this out to them, they uploaded a 3 MB version which did contain some pages (the last two were still empty). According to the meta information of that file, the software is registered to “Roger Rabbit.”
Slide 3 of that presentation contained a URL to beta.volltextsuche-online.de. That site is password protected. However, the presentation [PPT] also contained the user name (“admin”) and the password to access this site.
VTO as of February 2007 almost looks like the VTO I saw half a year ago in Frankfurt, including some of the typos on the user interface.
If you do a full text search for the words “der OR die OR das” (“der” = “the”), there are 16 books found. It is fair to assume that this is the complete number of books online on VTO. In order to have a look at the content, one has to register with a user account at VTO. However, it does not verify the information you enter, it does not even check if the email address is correct. No email verification link is sent, you are instantly logged in.
Turning pages can be done via two arrow buttons. After viewing more than 5 pages, you are asked to buy the book. If you go back to the search results and click on another hit of “der | die | das” (such as the sixth page), the counter is reset and you are free to watch another 5 pages.
Proof of concept: downloading a whole book
Indeed, the right mouse button is disabled, so you can’t simply use “save image as..” to save a page. However, “modern” browsers like Firefox (I haven’t tested others) are able to list all the objects of a page separately via Tools ... Site Info ... Media ....myHtml1.jsp is the URL of the page image you are currently watching. It is a png file.
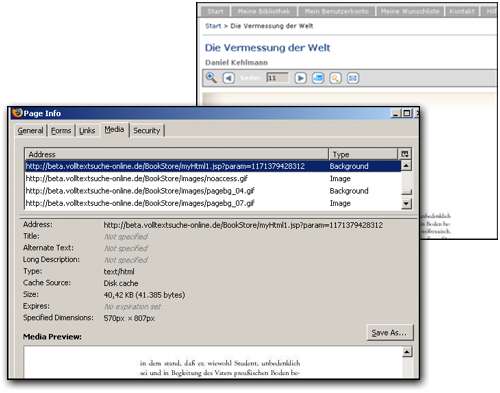
As a very lame “proof of concept,” I was able to download all the 303 pages of the bestselling book “Measuring the World” by Daniel Kehlmann. The image quality is rather poor, however, you can read the text and I guess you could even OCR it. Downloading 303 pages with no extra tools other than a standard Firefox 2 browser took about 3 hours (I admit, there were many interrupts such as chatting with friends, having lunch and so on). No “hacking” was involved and this task can be pretty easy parallelized. Or scripted, for that matter.
If you happen to use web browsers more than once in a month, you might ask “so, what is so special about this?” The technical answer is “nothing.” The process of displaying something digital is the same as copying it. You can’t prevent users from copying something if you want to have them watch something. This insight might be new to book publishers, I guess, even if books behave very similar in this respect (does anyone remember the password protection of SimCity 1 with dark-blue text on light-blue background?).
Besides the technical answer, there is a political one. The ability to save pages from web sites was one argument in the motion for the preliminary injunction against Google. Page 13 of the motion [PDF] reads (rough translation):
Even if the defendants [Google Inc. and GmbH] are attempting to establish technical mans of preventing third parties to copy the works and to download them, it is known that there are as of today no technical means of preventing available which are not “cracked” yet. Especially in programs like the book search, there are internet professionals who make it their mission to circumvent the protection measures and to provide a large audience free access. We
are referring in this context to the page GooglePrintSpeichern
where it reads:
“How do you save the images provided by Google Print? Here are our
two favorite methods in a short how to:”
[...]
As soon as the protection measures are circumvented and the works are feely accessible, any kind of usage including the distribution to a
larger audience and manipulation via mouse click is possible. The
plaintiff wants and has to prevent this in the interests of its
authors.
It should be clear that this statement is mixing cause and effect. It is VTO that is making these books available online in full text. There are no technical measures of prevention, only annoyances with no effect whatsoever. (Google says that there are parts of the books they don’t display at all, and soo far, this appears to be the only measure to prevent copying a complete book.) The Börsenverein supported this motion for a preliminary injunction against Google Book Search. If you apply their reasoning on VTO, their own project becomes “illegal.”
It is noteworthy that the same software is also used by the Macmillan New Writing Publishing house (also apparently with 16 titles).
I was unable to find any mentioning of DRM measures of protection in the draft contract between VTO and the publishers [PDF]. §3 tells the publishers to protect their user accounts. There is no obligation for VTO to protect the content from “unauthorized” usage. §3 (obligations of the publishers) lists several rights that are granted to VTO. Here are some:
- The right to copy the content unlimited times
- To store the digital content “in a digital memory”
- To store the digital content in electronic databases or to let it store in databases of search engines or to combine it
- To make the content public
- To let the users store the content (for free) or to let them print it completely or in parts
and so on. Full text in German Legalese is §3 (5), especially (b).
Another Google killer?
I am currently unable to see VTO as a competitor to Google Book Search. The Börsenverein has often indicated that they would like to sublicense the content to search engine providers under their own conditions. In order to achieve that, they have to get this system running. There are several key decisions which make VTO rather unattractive. The German book industry might have problems in providing the right PDF files to participate in VTO. The annual fee will make it unattractive to let books in that system once they become part of the backlist (in December, some publishers released their “worstseller” list. If your book gets only sold twice a year, 17 Euro annual fee seems rather high). Every reason to participate in this project also applies to participating in Google Book Search, except one: This project is a “domestic” solution. I fail to see how that perspective can outweigh the downsides.
Update: The organization behind VTO removed the PowerPoint linked above and issued a statement.
>> More posts
Advertisement
This site unofficially covers Google™ and more with some rights reserved. Join our forum!