Monday, April 14, 2008
Google Data Center Locations (and a Sidenote on Supercomputers)
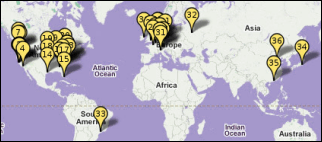
Google hosts what might be the world’s biggest supercomputer owned by a single company*; rather than a single machine, it’s a dispersed network made of smaller machines, though. Now Pingdom (a neat paid service that can alert you when your site is down) put together a map of Google data centers based on approximate information from the unofficial Google Data Center FAQ. Pingdom writes, “If you include data centers that are under construction, Google has 19 locations in the US where they operate data centers, 12 in Europe, one in Russia, one in South America, and three in Asia. Not all of the locations are dedicated Google data centers, since they sometimes lease space in other companies’ data centers.” But as the unofficial FAQ disclaims in regards to the number of data centers, “Nobody knows for sure, and the company isn’t saying.”
*The world’s biggest supercomputer owned by no particular single entity, on the other hand, might be the web itself – the global consciousness, if you will. It’s made up of us humans and our thoughts, but if we want to approach it in technical terms (which is just one of the many ways to see it), all of its nodes are individual sites crunching information day in and out. A blog and forum like this, for instance, is crunching information related to the subject “Google,” but there are other nodes covering politics, art, technology in general, sports and entertainment, and so on. Each individual node can reprocess the output of another more specialized node for a given subject. As individual task outputs are cached under permalinks, the solving of new tasks is sped up; e.g. to integrate a bit of another topic into a blog post I can jump over to a Wikipedia entry to find the cached “preprocessing” of hundreds of other people, all of who in turn might have used information from all over the web.
Some nodes are filters or prisms to the online world (e.g. a link blog or feed reader); some nodes are aggregation meeting points for users (e.g. a forum or wiki); some nodes deliver input from the real world (e.g. a webcam or a traditional news site); some nodes are corrective nodes to other nodes (e.g. a watch blog, or the comments in a blog); some nodes determine ranking of importance (e.g. Google); some nodes are gateways to channel “processing power” – our thoughts applied to a particular subject –, determining which subjects are worth crunching (e.g. Reddit or Digg). Over time, the system at large may reject nodes that do not interact (like nodes causing censorship, nodes behind paywalls, nodes that don’t reintegrate diverse feedback due to a conflict of interest), and emphasize such nodes that do (like nodes using free licensing, open comments, embeddable widgets, or standard registration systems).
But in all this, different nodes in the system may have opposing information points; if the cumulative balance of these information points is about equal to each other, then you won’t be able to find an easy answer – if you request the result to the question “when was Cary Grant born?” via a search engine, you will get a rather plain answer, whereas a question like “who is the ideal candidate for my country’s presidency?” might yield ambiguity. As this network of opinions is so loosely coupled by design, no instance can single-handedly resolve such ambiguity, or – at the moment – truly tell us which questions are worth asking in the first place.
[Thanks George R and Pingdom!]
>> More posts
Advertisement
This site unofficially covers Google™ and more with some rights reserved. Join our forum!