Thursday, September 17, 2009
By Acquiring ReCaptcha, Google Acquired a Crowd Computer Along the Way
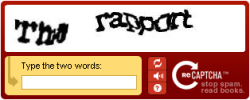
As previously mentioned, Google has acquired reCaptcha, a company providing those hard-to-read Captcha tests to tell robots and humans apart on websites (e.g. to protect a comment form against automated spamming). The twist with the highly popular reCaptcha is that it’s also used to help turning scanned books into searchable digital text... something Google aims to apply for their books and newspaper digitization projects, too, to help with the quality of their existing OCR (Optical Character Recognition)
For all the websites out there using reCaptcha – Google says there are above 100,000 – this now means you’ll also help Google’s efforts now. (You continue to get something in return, of course: a form of free spam protection for your site.) The reCaptcha technology might have been feasible to duplicate for Google, but the installed existing user base for reCaptcha is possibly the actual gold Google was after. ReCaptcha mentions they’re serving 30 million Captchas daily and that generally, people spend roughly 10 seconds on a captcha – that’s quite some human computing power Google snapped up there.
Technically, here’s how reCaptcha works. Captchas (short for Completely Automated Public Turing test to tell Computers and Humans Apart) are deliberately distorted to make them hard to read, so that they can’t be easily solved with existing OCR algorithms. At reCaptcha – which webmasters can easily plug-in to their existing forms and configure via e.g. a JavaScript API – you’ll always be presented with two, not just one words. The trick is that reCaptcha already knows one of the words, but wants you to help solve the other word (if enough other people solve that other word similarly, the system gains confidence that it now knows what that word reads). So you can say one word is the actual Captcha test word... while the other word deliberately spends more of your time than needed for the robot test by letting you turn books into text. It’s these extra seconds that you spend solving the secondary, unknown word that make up the CPU of that crowd computer Google now owns.
Right now, Google can use this crowd computer to improve searching and highlighting text for projects like Google Books. Improving by correcting old words, increasing their confidence threshold, or cracking new unknown words – and perhaps letting their software learn from its mistakes, or by running automated tests against reCaptcha when they try out new versions of their OCR. But who’s to say that in the future, we’ll not be solving other captcha tasks? Telling humans and bots apart is not necessarily restricted to text-reading tests. There are other puzzles out there which are tough for today’s AIs, but easy for humans, which might benefit a Google project.
For instance, a captcha may show you a thumbnail collection of a dozen images and ask you to click on all images showing a cat. (I’m not sure how feasible this particular example would be for Google, but it’s just to illustrate the general different directions captchas can take.) For most images Google knows whether it’s a cat or not, but for one image, Google only suspects that it’s a cat based on keywords found on the same page the pic was hosted on. If many people click that picture, Google may gain confidence that it’s indeed a cat (or conversely that it isn’t), and rank it accordingly in Google Images.
For such alternative captcha systems, take a look at Microsoft’s Asirra project, KittenAuth, or Google’s own foray into the field. These are straightforward applications; even more power could be unleashed if any company figures out a possibility to break up bigger questions into easy humanly solvable chunks, which would – after being solved – be merged to form the deeper answer. (Perhaps both the process of breaking up the question, as well as merging the individual solutions together again, could be themselves human computing powered.)
Now, it’s worth keeping in mind other, older parts of Google’s crowd computer. Here are some examples:
- whenever you mark a Gmail message as spam, you potentially help Google to determine what spam looks like
- whenever you click on a Google search result (and then either continue your search afterwards, or be gone to the other site for good), you’ll give Google some indicators to the usefulness of the site
- your searches may power prediction machines for things like flu trends; they may also help Google build a “database of intentions”
- calling 1-800-GOOG-411 allows US users to say what business they are looking for and to be then connected with that business, but the reason Google really did this, according to Google’s Marissa Mayer, was to “to build a great speech-to-text model ... that we can use for all kinds of different things, including video search”
- when you include Google Analytics in your site, you could help Google spot global traffic trends and patterns
- a game called Google Image Labeler directly helps Google to associate the pics of Google Images with keywords
Google can potentially use any and all interaction with their sites as data points to power yet other calculations. What’s the hottest spot in town (as a purely hypothetical example)? Let’s see what areas on Google Maps those people who fall into the younger age group – determined by their Google search patterns – look at most often recently! ... What are the most popular websites out there right now? Let’s see which URLs are being forwarded the most in Gmail right now. ... Who are your friends? Let’s look at which Google Latitude users – those who allow their location to be tracked – are often found in your vicinity.
There’s nothing inherently bad about this; user attention as well as user information continues to be the currency in many parts of the online world, like it is the case with the ads Google displays on search results (many a webmaster’s sites are financed through ads, too). Often we prefer paying with attention (or sharing our information) to paying with money; it feels “free.” Applying a broad definition of the word Google’s programs are not free though – it’s just that you’ve signed an inherent contract with Google to use their apps only as long as you trade in your brain cycles in return. Google’s terms of service point 17 translates this to legalese: “Some of the Services are supported by advertising revenue ... In consideration for Google granting you access to and use of the Services, you agree that Google may place such advertising on the Services.” With reCaptchas too the agreement is built into the technology, as you cannot display only the single test word needed for that “Turing test.”
As it is, perhaps Google is not only owner of the biggest electronic computer in the world (their giant server farm), but also owner of the biggest crowd computer in the world. If this sounds scary, remember your attention also acts as a vote – you might think of the alternative model in which Google is simply a building block in civilization’s computer, granted permission to handle a large part of the calculations as long as it works.
Please comment in the existing thread.
>> More posts
Advertisement
This site unofficially covers Google™ and more with some rights reserved. Join our forum!