Wednesday, June 23, 2004
Screen-scraping With PHP5
PHP5 (the latest PHP scripting language release soon to be final) opens up great new possibilities for developers. One of them is easy screen-scraping.
PHP5 adds real and standardized XML capabilities, something native PHP4 lacked. This means you can load an XML DOM object and select elements using XPath.
Loading any HTML file
Now not only can you make use of well-formed XML files, you can also grab any HTML tag-soup. As you may know most files on the Web are not valid HTML, let alone XML/XHTML. Parsing them with a strict XML parser would yield nothing but error messages.
The simple but powerful function we need is called "loadHTMLFile" and accepts any URL as parameter.
Here's a sample of its usage, which will grab the Google News headlines and format them as simple linked HTML list:
<?
header("Content-type: text/html; charset=utf-8");
?><!DOCTYPE html PUBLIC "-//W3C//DTD XHTML
1.0 Strict//EN" "DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml"
xml:lang="en" lang="en">
<head>
<title>PHP5 Screen-Scraping</title>
</head>
<body>
<?
$dom = new domdocument;
$url = 'http://news.google.com';
@$dom->loadHTMLFile($url);
$xpath = new domxpath($dom);
$xNodes = $xpath->query('//a[@class="y"]');
echo '<h1>Google News Headlines</h1>';
echo '<ul>';
foreach ($xNodes as $xNode)
{
$sLinktext = @$xNode->firstChild->data;
$sLinkurl = $xNode->getAttribute('href');
if ($sLinktext != '' && $sLinkurl != '')
{
echo '<li><a href="' . $sLinkurl . '">' .
$sLinktext . '</a></li>';
echo "rn";
}
}
echo '</ul>';
?>
</body>
</html>I highlighted the two relevant lines (which are preceded by an "@" symbol to supress error messages, something which is necessary at least in this version of PHP5 when you use loadHTMLFile on non-XML files). So basically the script above says "Get the Google News homepage, and grab every link (those with a class "y" which denotes a headline in Google's HTML), then go through all links and output them again".

Instead of the Google News homepage, you can extract data from any page which is accessible online. (Note that most sites, like Google, disallow this kind of automated reading of their pages in their Terms of Service.)
Installation Notes for Apache/ PHP5
To run the sample on Windows XP Home Edition (which does not come with IIS), you need to:
Install Apache 2 as found on the Apache download page (the setup takes you through the process).
Download PHP5 from the PHP download page (unzip files in e.g. "C:php").
Stop the Apache server if it's running.
Copy "php5ts.dll" from the PHP directory to "C:WINDOWSsystem32" (or whichever is %SYSTEMROOT% on your machine).
Open the "httpd.conf" file in the Apache "conf" folder and the two following lines at the end (adjust to fit your directory):
LoadModule php5_module "c:/php/php5apache2.dll" AddType application/x-httpd-php .php
Start the Apache server again.
Now you can put your "*.php" files into the "htdocs" folder in the Apache installation (move existing default files into a temporary folder to get them out of the way and create your own "index.php"). Enter "localhost" into your browser and off you go. (If you feel like you can continue by installing the free database system MySQL, which should make this server scripting package complete.)
And if you want to run PHP5 on a public Apache web server, you may need to ask your hosting service to upgrade from PHP4. And there will be good reason for an upgrade. With PHP5, the open source approach LAMP – Linux Apache MySQL PHP/Perl/Python – is about to get even more exciting.
Googlebot Alert
If you want to know when the Googlebot indexes your page, you can insert the following PHP code at the beginning:
<?
$email = "yourname@example.com";
if( eregi("googlebot", $_SERVER['HTTP_USER_AGENT']) )
{
mail($email, "Googlebot Alert",
"Google just indexed your following page: " .
$_SERVER['REQUEST_URI']);
}
?>(You need to replace the email address above with yours.)
[Thanks to Marshall.]
Justin Flavin adds the following "will show you how many times Googlebot has visited your site today":
grep "$(date +"%b %d")" access.log | grep "Googlebot" | wc -l
Gmail Hype Ending

I think the point arrived there are more people offering out Gmail than those wanting Gmail. “I * Gmail invites” yields 153 results (that’s still less than the 807 pages containing “I want Gmail”). And in my latest Gmail thread where five more Gmails can be won, half the people replying offer Gmail invitations themselves. If Google wants to keep the hype going they better open Gmail to the public within the next days.
PageRank Checksum Algorithm on eBay
Usually you can only check the Google PageRank for a given URL by using the Google toolbar. But if you want to program a tool which incorporates a site’s PR you need to know how to find it dynamically. eBay comes in handy for this purpose: a PHP script calculating the Google PageRank checksum is currently being auctioned with a starting bid of $500.
Screen Space
Practically any web page layout can be categorized into four* distinct spaces:
- Context (Logo, Navigation, Related Links, ...)
- Content (Article, Movie Trailer, Photo Gallery, ...)
- Advertisement (Animated banners, Sponsored Links, ...)
- White space (empty areas)
All four have their reason of existence. Context will let you know where you are and where you may go if you want to stick to this site. Advertisement supports the webmaster, but only works if the visitor is attracted by the actual content. And finally white space cleans the design, leaving you room to think, and it also separates the other three areas.
*Of course, there are nuances in-between these categories. (For example Google ads are usually highly relevant, coming closer to be actual content.) Context may also be highly functional and transcend into what could be called “application area” (like Google’s search box).
While most web pages feature all four parts in their real screen estate, some put heavier focus on a certain part than others.
Usually what we think of as uncluttered, focussed design would be along the lines of 70% content, 10% context, 10% advertisement, and 10% white space.
A cluttered page on the other hand would consist of say 60% ads, with 10% content and the rest context and white space. We might still find our way around easily (e.g. by scrolling and pretty much ignoring everything else but the main text), but the page still feels noisy and annoying.
I used the colors red, green, gray and white to visualize the different sections on three different types of web sites. Let’s start out with German news magazine Spiegel Online (high noise), then look at gadget Blog Gizmodo (average noise, not really affecting the user experience negatively), and finally Google (usually low noise, though the example search for “web design” is highly noisy for Google’s standards).
| Spiegel Online | |
|---|---|
|
|
| Gizmodo | |
|
|
|
|
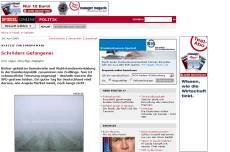
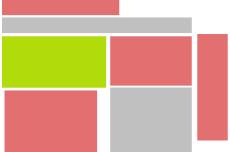

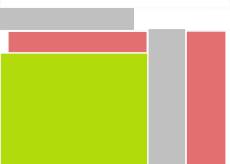
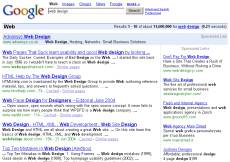

You might want to paint the same colors over your own web site now. If you think content is what drives visitors to your site, check how well it fares in comparison to other section of your page.
Googler Builds Palindrome
This is the story of Google’s director of search quality Peter Norvig calculating what must be the world’s longest palindrome. It is also a story about how, thanks to Moore’s Law, “it is becoming easier to do big things”.
>> More posts
Advertisement
This site unofficially covers Google™ and more with some rights reserved. Join our forum!