Saturday, March 5, 2005
Copyright?
Copyright is complicated. Too many shades of gray. Especially in the digital world. I’ll give this post to the public domain, so share it all you like. But it’s not always that easy.
Take images you put on your web page, for example. Maybe you made the photo with your digital camera. Maybe it’s a photo of a group of people. Are you allowed to publish it without asking anyone? Would it matter if you start charging for it? Would you need to ask all persons on the photo for a permission?
Let’s say you make a photo of a new painting. There’s not much else on the photo but the painting itself. The painting is copyrighted. What happens to your photo – who owns the copyright?
Let’s say the same painting is in the public domain according to the country’s laws. Who owns the copyright now? If you publish it, is everyone else allowed to re-publish it on their site without giving you credit?
(Or maybe our rule-of-thumb should be “do all you can get away with?”)
And what happens when other countries, which also access your photo, have different copyright laws, and the photo is not in the public domain according to their laws? Or what if you made the photo in a country where the painting is not in the public domain, but you upload it to a server where it is? Or vice versa?

Copyright is complicated! According to US law, and this is off the top of my head as I’m no expert, books will be in the public domain – copyright-free – 75 years after publication. That’s how I was able to compile this illustrated Alice in Wonderland on my Authorama site (I invested $5 at Google Answers prior to publishing it because I didn’t know the copyright to the images – the text on the other hand came from Project Gutenberg, so I suspect it to be in the public domain). If the creative work in question is not that old, you can still use it “fairly”. Whatever exactly constitutes fair use is up to your intuition, but as soon as you get a cease-and-desist from a lawyer, it’s probably more related to your law knowledge (or the amount of money available for you to pay a lawyer). So cease-and-desist will often reach its goal even if law would think else. Simply because people are careful!
Sure, the Creative Commons make it easy, but they rely on everyone to join. I can publish the following because it’s been declared to be in the public domain at OpenPhoto:

Sometimes, copyright is a strange system. It could happen that when law changes, works which already were in the public domain, now fall into the copyright zone again. What if you already re-published the work, while it was public domain? Sounds like you’d be screwed.
But publication dates illustrations may not even fall under the 75 years rule. The death of their illustrator is the decisive issue. Work of someone who died in 1914, thus, could be freely used by you. If you know when someone died. You won’t know by going over to Google Images to find pictures. You won’t even know for sure when the site says the work is in the public domain. After all, the site’s creator might have been misled.
I once made a small video of a TV show. I first published a longer version, several minutes, then quickly cut it to just about under a minute. Still the production company in Germany asked me to remove it. So I did.
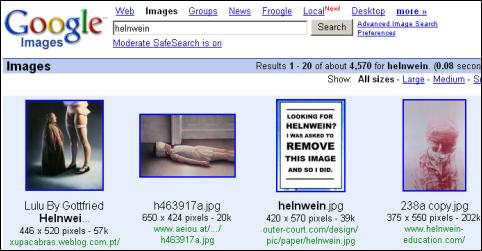
Back in school, in art class, I painted a screaming man based on Helnwein’s work. (Helnwein was working from a photograph he made.)

I scanned this thing later on and put it on my web site. Again, a cease-and-desist arrive some years later from the Helnwein corporation. They were mainly worried about the fact my image was ranked top for “Helnwein” in Google Images. It still is, even though I complied – just enter “helnwein” into Google Images and you will see it in the top row. The image is painted over by a big note: “Looking for Helnwein? I was asked to remove this image and so I did.”
It’s complicated, at least to me! And so far I was talking about clear-cut traditional cases of creative ownership. Let’s move to re-mixing content, or creating something which happens to look like something else. What happens when I create a caricature based on a copyrighted photo? According to the copyright law, even derivative works of copyrighted works are breaking the copyright law! But what constitutes derivative work? What if you change 10% of the pixels? What if you apply filters? Invert or mirror it? Make a collage with 50 other images, 25 of them copyrighted? What if you change 50% of the pixels? What if you change 90%? (100%?)

Effectively, I’d need to start studying copyright law to be a publisher in today’s digital world. So they say it’s easy, like blogging – one click publishing – but in fact it’s not! Can I use this image? Is this quote too long? Do I have the right to the image I made? (I might have made a photo of a Mickey Mouse cover copyrighted to Disney! Disney, by the way, is always big on remixing existing content, as Lawrence Lessig in Free Culture illustrates.) What if I distort the image? Rephrase the quote? What if I don’t credit? Does giving credit make a difference? And which copyright law are we talking about anyway? My server’s in Germany. My audience is all around the world.
Do I need a patent to be really safe? A trademark? Anything else to remember? Or isn’t my work automatically copyighted?
You are not supposed to sing Happy Birthday! Is that true? If I rent a digital movie at CinemaNow.com, it comes with Microsoft’s DRM (“plays for sure”) limited-licensing locks. So I couldn’t just burn the thing on disc and put it in my player connected to the tv, because my player doesn’t understand DRM! Back in the 80s, we were allowed to make copies of VHS and music tapes. Or were we? I think so.
It’s complicated, but it’s getting still more complicated. I was only talking about manual copies and remixing so far. What if we automate it?
Google Images is a great example of big-scale copyright-breaking. They take the images of people without asking, and they make copies (thumbnails) on their system, and then they display the whole caboodle on their website, and then they put ads next to it to make it commercial. Are the using my work but still respecting my copyright ownership? Does it make a difference when the user entered something to pull this out of the Google machine? Does it make a difference it’s only a thumbnail? Or that, in theory, I could use a “robots.txt” file to stop Google doing this? (I wonder, does Archive.org have the right to cache my content from 5 years ago? Doesn’t the browser always copy content too it downloads? Don’t proxies?)
(Who holds the copyright to my Usenet articles, by the way? Google Groups put them all on their server.)
At Feeeds.com, I collect different great RSS feeds on a single page. I even do what is called feed-splicing, by compiling different RSS feeds into one big RSS feed. On some items, you can post a comment. Is it my right to treat RSS like that? Is RSS copyrighted? I’m often asked why I don’t turn this blog’s RSS feed into a full-text feed. There’s two reasons for that: I want to know my audience, and services like Bloglines won’t tell me who reads what (not knowing who reads this blog would effectively deprive me of the energy needed to continue to write it).
The second issue is that other people take RSS feeds, like mine, and republish them instantly, but completely. (At Feeeds.com, I choose to only use the first 200 or so characters of each item.) These are often spam portals trying to fool Google and others into thinking they create up-to-date, original content. And they often pop-up in the top 10 for a variety of search queries. They might even have a successful cash-flow by sticking Google AdSense onto their stolen RSS feeds. Or weren’t they stolen? Are they just copied?
Yesterday, I created an image search engine based on the Yahoo API. Instead of delivering thumbnails, I deliver full images. Clicking on them reveals the site behind them. Is this OK? Does image size make a difference? Is this kind of automated, user-based image inclusion OK? I respect the “robots.txt”, because Yahoo does.
(What if the copyright holder cannot be found? Will works die because of that?)
It’s complicated because it’s a gray area. The recent Google AutoLink discussion shows that. People take a side, they either say “we may remix all content”, or the say “our content should stay as is.” Some think Google might be doing OK but set a bad example. Others compare them to Microsoft, who with their Smart Tags did similar (but, as opposed to the Google guys, intended to make it a default setting).
Over at CafePress, I created some t-shirts for this blog. Many of them, CafePress cancelled – copyright problems. This included a yellow t-shirt with a black pie.

Yeah, I called this the “Retro-gamer” t-shirt and I was clearly thinking about Pac-Man. I was also thinking: a filled black circle with a missing pie can’t possibly be copyrighted. Well, CafePress thought different.
This shirt, on the other hand, was OK – I asked Google Inc a while ago.

Interestingly enough, I wasn’t allowed to put the logo of this blog on a shirt (supposedly because it contains the trademarked word Google™).
But here’s a Renaissance masterpiece. I’m allowed to use it. It’s just so old. The Mona Lisa, La Gioconda, by Da Vinci, who worked day and night and wrote in mirrored script (and dug up corpses at night to analyze and dissect them – quite illegal at the time, by the way, even though it advanced the arts and sciences).

This was just my take on it at the Mona Mailart Show. I don’t know who, if anyone, owns the copyright.

So it’s definitely complicated, and I wonder if there’s a rule beneath all of it. Possibly intuition (that would be great), or common sense. Or some formula, upon which we can base all decisions (restrictions like 75 years, on the other hand, sound pretty arbitrary).
Is it OK to deep-link to a video without giving credit? Is it OK to cut a 10-second piece from a music MP3 to pass on? Is it OK to post the lyrics of a song onto a web page, when you typed it yourself after listening to the song? Is it OK to include another site in a frame? Or to directly include an image from another site on yours? Or a video? What about iframes? What about screen-scraping? What if the text is by Reuters? Was it OK for Andy Baio or me to put the Tsunami videos online? We didn’t know their exact origin, perhaps, or wouldn’t have cared if we did know. What if the text copyright is undefined, or undeclared? Does it matter if you put © 2000 on it? Does the number matter, or the little ©? Does the number have to be recent, even though the content is quite old? Are you renewing copyright that way?
Can you film someone on the couch who’s watching TV, and can you then film the TV he’s watching, even though that same TV is currently playing a show of The Simpsons? (By the way, searching for Simpsons in Yahoo Images is not safe for work because of adult “fan art” – probably a clear copyright breaker, even though it’s often the fans who promote a show and make it successful. In this case, they simply created what wasn’t there.) While we’re at it, can you cut out ads of TV shows when you record them? Can you block content you dislike? Can you block this content even if it’s supposed to be the creator’s revenue stream? Will that kill culture in general, or only that specific creator, or will it harm no one at all? Do online music download services hurt the music industry? Or are we just downloading what we can’t afford anyway, or can’t find in the first place?
Some clever people connected Google News Alerts, delivered via email, to their blog, by using Blogger.com’s post-by-email feature. Sort of spammy. Then again, there’s no human intervention – it’s all done by Google. Is the result of this a site that breaks copyright? (If so, who’s responsible? Google Inc?) Did all Google News sources agree to become such, and if they wouldn’t, could Google still scrape them? And isn’t Google News then obliged to give us users the same right, like to RSSify their news service?

What about the kid who bought a home computer back in the late 80s – and who wouldn’t have bought it, if not for the reason so much cracked games were available? What if this kid now buys about one game per month, but gets 100 cracked games for free every month? (Note: The same kid would never have bought that one game, if not for the fact the availability of 100 games would have convinced him to buy a computer!) What if the same kid, once grown up, now buys all of his software, but wouldn’t even be interested in computers if not for his illegal past? (And are adults more responsible in these regards?)
I don’t know. Copyright is complicated, but is there a simple rule all the complications are based on? A simple system so that publishing in the digital age becomes easy? A simple rule which we could look up so next time a big corporation comes along, we can point them to it and explain?
Long-time (and now micro-patroned) blogger Jason Kottke says:
“I got an e-mail from someone with a two-minute audio clip of audio of him losing, four days before the show was supposed to air on TV. I posted that to my Web site along with a transcript. A couple days later I got an e-mail and phone calls from a lawyer from Sony who asked me to take the clip down and remove the transcript, which I did because I wasn’t aware of my rights or what I could do and couldn’t do.”
It’s in fact so complicated that the big guys can just send the small guys (or even the medium-sized ones, like Jason), a cease-and-desist.
(Can I forward an email to a group of friends if the attached images are copyrighted? What if they happen to stand behind me watching me read my email? Can I create a program that publishes all my emails on my site, including the attachments? What if I never requested the attachments, but they’d now be automatically posted on my site? What about Gmail? They stick their ads next to copyrighted attachments!)
What happens when I provide a service to users to enter a URL on my web site, and then pull all images from that URL and link them on my site? Would that be legal? According to US-law, to global law, to German law? Is it moral?
I think Presidential speeches are easy – they are in the public domain the instance they’re published. Right? What about the rest of WhiteHouse.gov? (Speaking of which, is WhiteHouse.org, the copycat site, protected because it’s a parody? Does every law have that parody law? Can I steal content if I put it in the context of humor, because then it becomes a safe parody?) Oh, and book covers I think are in the public domain too, at least in the fair-use domain.







(What about ownership if you produce something at work?)
What happens when I create my own content, and I think it’s original, but somewhere else in the world the same text, idea, shape, technology, illustration, or painting exists... and is copyrighted? Will my work be illegal because I didn’t know all other work that came before me? What if I write a randomizing program which happens to create copyrighted work? What if I make sure Google picks up my randomizations and people will now find them? What if the program is great at learning from other people’s works (such as paintings or novels)? What if it can, in 30 years, adapt the style of Stephen King, and sell King-like novels? Is that OK, according to the copyright law? Would it change anything if Stephen King is dead by then and there’d be no other way for the world to read more King-like novels?

It’s complicated, and as long as we don’t have definite answers we keep pushing just to make borders visible. Maybe a decade from now, those publishing content will have it all figured out for them. Maybe someone found the rule. Maybe, just maybe, there’s a big machine where you can input your content, and it will output the legalese and where (if) you are allowed to use this content. (The wizards of Googlebot are good at producing big machines, but this one may be too complicated even for them.) Maybe it works so globally we can all have a vote in the output it produces. Maybe it will give us what we don’t have today: the answer to copyright.
>> More posts
Advertisement
This site unofficially covers Google™ and more with some rights reserved. Join our forum!