Monday, June 18, 2007
Sebastien Marcel on Face Recognition
 Google recently released an option to show faces only in their image search results. Via instant messenger, I talked to face recognition software expert Sébastien Marcel about this subject and more.
Google recently released an option to show faces only in their image search results. Via instant messenger, I talked to face recognition software expert Sébastien Marcel about this subject and more.
Hi Sebastien! Can you tell us a little bit about yourself – how old are you, where do you live, and what do you do?
I am 34. I leave in Martigny, Switzerland, and I work in a Research Institute called IDIAP. I am a research scientist in Image Processing and Pattern Recognition applied to Biometric Authentication and Multimodal Interaction. See my homepage for more details. I am particularly interested in the problem of face detection and recognition in images and videos.
What are some of the typical applications where people need image recognition?
Photo cataloging is an obvious one, but also biometric authentication (access to a bank account or cash machine, PIN code replacement on the cell phone or any cards), more secured applications such as identification of people such as terrorists (if possible), and more general applications in the domain of multi-modal interaction where a user can interact with a computer using the voice but also using gestures... you need to be able to recognize facial expressions, or to monitor elderly people and for that you need image processing and more particularly face detection and recognition.
Is face recognition very different from recognizing say a car, or an elephant, within a picture?
In practice yes. We are using very specific algorithms, it is very different with other objects. For instance, cars and other objects can be seen from any point of view while for a face this is more restricted. It is frontal most of the time, rotated in the plane or out-of-the plane of the image.
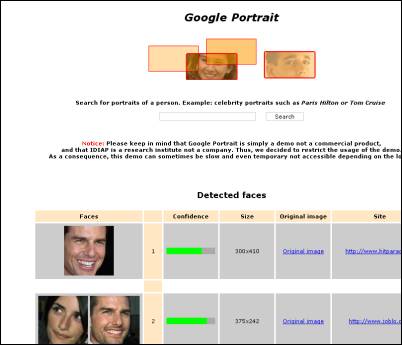
I see. Let’s take one of your applications, Google Portrait, which returns a list of faces only when you enter a search query. Can you explain the broad concept of how the face detection algorithm behind that works?
Yes. There are 3 main concepts:
- scanning
- classification
- and merging
Scanning consists of searching in the image at any scale, location and eventually in-plane orientation for a face within a fixed size sub-window.
Classification consists of deciding if this sub-window is a face or not and if yes, its pose (frontal, +- 25 degrees rotated, +- 45 degrees, +- 90 degrees, ...).
Merging consists of taking all sub-windows classified as faces and merge them when they overlap.
Classification is the most important step. Indeed, it has to be very fast because you need to test several thousands of sub-windows per image depending on the size of the image and on the size of faces you want to find.
Of course you can use tricks to reduce the number of sub-windows like focusing on skin color but this is not applicable in most of the cases because you can have gray-scale images, and also because of illumination that affects the color. If you take 2 movies such as MI2 [AVI] and Matrix [AVI] for instance, in the first case you can have skin everywhere at the beginning because you have rocks with skin-like color, and in Matrix all faces are “greenish” and people wear sunglasses (See more examples.)

When is a sub-window a face? When it contains a nose, or one eye, or does it have to be a complete face?
Your question is related to the general classification problem, I will try to answer. Best techniques don’t try to decompose the face into parts to say this is a face because if you do so, let’s say the face contains a nose, a mouth and eyes, you have (1) to find a way to detect those facial features and (2) you are in trouble to find a face if a feature is missing. So best techniques are based on so-called statistical models that learn from data:
We generally need a large number of faces under various conditions (several databases exist and it is easy to produce a database of several thousands of faces) and we also need image examples without faces. From those 2 sets, we use a training algorithm that finds discriminant features (pixel values or anything else computed from the image) between faces and non-faces.
OK. Do you end up with a “confidence” factor that a particular image contains a face after the algorithm did its work?
We obtain a confidence for each sub-window detected as a face and then after merging, it can be as simple as the average of confidence.
If two faces are really close together on the photo, doesn’t that cause trouble with merging overlapping areas?
There is an overlap threshold which is chosen accordingly but if 2 faces are too close they can’t be close enough to overlap at 60%, right?
Which kind of faces other than human faces would such an algorithm detect – what about cartoon faces for instance?
It really depends on the algorithm, some detects only human faces and others are less restrictive and detect cartoons or even monkey faces... everything which is a human-like face.
So if I train the algorithm on say Walt Disney cartoon faces, it might detect Mickey Mouse in a picture?
Yes possibly, but if you use only cartoon faces you might also end-up with a detector that detects more non-faces as well; I mean it makes more mistakes because it’s more likely to find cartoon-face structures in complex background pictures (trees, forests, ...).
Have you seen Google’s face detection in Google Image search, where you can append a parameter to the URL and it will return faces only? What do you think of its quality?
Yes I’ve seen it, and I am not surprised, Google acquired a company specialized in face detection and recognition last year (Nevenvision) and Google also has very good researchers in house. About its quality, it is impossible to say objectively as (1) we don’t know if the detector was really applied or if images were tagged manually :-) but I guess no, (2) we don’t know how many real faces were missed, (3) we don’t see how accurate the detection is as the face is not framed by any visual cue (a bounding box for instance), and (4) if the detector is fast as all the process is done in batch. So assuming the detector is really used, I think the result is quite good as it produces results with faces. But a nice thing to know the performance would be to directly filter the result of a Google Image search, as we did on Google Portrait.
Yeah, I noticed your Google Portrait application is incredibly fast.
The face detector is indeed near real-time, it is used in various real-time face tracking demos and several face recognition systems that need face detection such as BananaScreen.
By the way, it is fast but it is not at all optimized. It is currently based on an Open Source Machine Vision library we developed, and that provides various machine learning and image processing tools. We estimated that a specific implementation of the detector could increase the speed by several times.
Interesting. Can you tell us some of the common obstacles to face recognition – e.g. if a person turns away their head, I guess it will become harder?
Yes, the pose in face recognition is one of the problems, but not the biggest. The biggest is certainly illumination that drastically affects performance.
Now you mentioned BananaScreen. I installed this today and was extremely surprised at the great results. To give those who don’t know it an introduction: BananaScreen connects to your web-cam and then detects your face... when you’re gone from the computer, the screen will be locked, and when you (and only you!) return, it will unlock without you having to enter a password! Did you create/ co-create this software? Is it commercial?
We completely developed the core software and the graphical user interface for a Business Experience in collaboration with students in marketing. All my former PhD students, especially Yann Rodriguez, and our developers at IDIAP did a wonderful job to port the prototype from Linux to Windows. Anyway, you can have more information by directly contacting the BananaSecurity team or using their forum, they are very reactive. For the moment, the software is free because we want to collect feedback to improve it and to make it more friendly and reliable. But in the end we plan to commercialize other versions. Again contact bananasecurity.com for more details.
In BananaScreen, added to the face detection, there’s face recognition, or authentication... the algorithm must know that it’s me. How does that work?
You mean in general or in Banana specifically?
I mean in general – but also in Banana, if there’s a notable difference.
First it is important to clarify some terms and to introduce some definitions. Face recognition is the general term of the field. Then it is decomposed into 2 topics: face identification and face authentication (also called verification).
- Face identification is the task of identifying the person in an image, ie attributing an ID to a face image
- Face verification (or authentication) is verifying that a face image correspond to a given claimed identity (cash machine example)
BananaScreen is an example of face verification.
Then definitions: What we call a “model” (also called template or biometric template) is a representation of a known person. A known person is often called a client in face verification. An unknown person is called an impostor.
Something else: Face verification is an example of an open set scenario, that means that the number of known persons is NOT fixed and that persons to verify are NOT necessarily from the pool of known persons. In face identification, we can have the two cases: open set and close set. Close set is when the number of persons is fixed (like family members) and persons to identify always belong to the group.
Now how does it work? Both verification and identification relies basically on same algorithms: a face image is compared to the model and it gives a score. In verification, this score is compared to a threshold, if above the claim is accepted (this is a client), otherwise it is rejected (this is an impostor). In close set identification, we have as many scores as models because the face image is compared to all client models, then as this is a close set, the model that provides the best score gives the identity. Open set identification is a mix between verification and close set verification, i.e. close set verification + a threshold!
So I guess verification faces the same obstacle as a spam filter: if you set the threshold too low, too many impostors get through, and if you set it too high, the actual client won’t be accepted.
Exactly, we call those errors False Acceptance and False Rejection, ideally we want both to equal zero!
So how do you compute the “acceptance” score then?
It depends on the representation you choose for the model. Let’s say to simplify that the model M is simply the image of the face, then computing the score between a new face F and the model M can be simply a distance (Euclidean for instance) between M and F!
In reality, it’s not possible to directly use the image and its pixel values because of the high dimensionality of data (The Curse of Dimensionality) and the large variability; computing such a distance in the space of pixels will be useless. Take a face image in gray scale of size 64x80 pixels, this is not a big image right, but if you consider all the pixels, you have more than 5000 of them, which means computing a distance between 2 arrays (also called vectors) of 5000 numbers. Computing a distance in such a large dimension does not make any sense on images affected by so many variations (light, pose, ...).
OK.
So there are 2 main techniques:
- Global approach (also called holistic approaches): it basically consists of reducing the dimension of this 5000 vector into a lower dimensional vector, few hundreds or less, with linear algebra techniques such as Principal Component Analysis (PCA), Linear Component Analysis (LDA) and their variants, that preserves all necessary information that characterizes a person and that differentiates several persons. Then computing the distance in this smaller but more informative vector is more efficient than in the original space.
- Local approach: the image is decomposed into parts (regular blocks of instance), and for each of the parts/blocks a feature vector is computed instead of using pixels themselves (same reason as above). This computing can be as simple as a compression, 2D Discrete Cosine Transform (DCT) such as used in jpeg, PCA or LDA as above but locally, or any other transformation. Then the score will be a kind of “weighted sum” of local comparisons between parts/blocks of the face image and the model.
Then depending on the technique, the model can be (1) a stored representation of global or local vectors, (2) a statistical representation trained from those global or local vectors such as for instance Gaussian Mixture Models. Both have advantages and inconveniences.
OK. Now I was curious if you can cheat these authentication systems by printing out an image of the face and holding it up in front of the camera. Is that possible?
It is always possible to cheat – and a part of the game is to make it more difficult to cheat. But currently, yes, using a picture you can fool the system but NOT systematically, as it depends on the recording conditions and on the printed image. We are working on different counter-measures to deal with that, such as looking at face/lips movement.
I see. What would you say is the status of face identification today? Let’s take a practical example; let’s say I’m the owner of YouTube or a similar video service, and have a database of 10,000 actor portraits connected to their names. Is it feasible today to go through my video database and automatically associate the cast to the video clips (if they’re Hollywood-type movies)? And possibly even get the title of the movie this way, because I have another database which associates a cast with a movie?
It is possible to do something like this yes, but this is (1) very difficult as you need to have a lot of different expertise in face detection, face alignment (you need to locate very precisely each facial features after detection to expect an accurate face identification), (2) you will probably not have good performances as a lot of faces will not be identified and you will most probably obtain a lot of confusions (Tom Cruise being recognized instead of somebody else).
Of course, this is purely using automatic image recognition techniques, because you can probably use a lot of tricks such as using meta-data information to reduce the pool of actors to search for, or by using all possible face images from all existing movies for your model (in this case you have a high chance that the face you are looking for is very similar to the one in the database).
The main problems are: pose (the face can be turned in any directions), the illumination that can be very different between the database and videos, and occlusions (glasses, sun-glasses, ...).
To continue on the subject of “auto-tagging” existing image or video data... how feasible is it today to auto-tag a photo catalog? Say I’ve uploaded my vacation pics, and I now wish for the software to automatically assign the keywords “car”, “cat”, “beach”, “Susan”, “cocktail”, “sun”...
Hum, we are moving out of my field of expertise. So I can’t tell you much. The main problem with auto-tagging is that tags can be anything and that different persons can use different tags for the same image. I strongly believe that this kind of thing should be user specific, but I agree that some general tags are commonly used. There are various techniques to do auto-tagging, they consist of building a statistical representation (again :-)) of image features (blobs, color histograms and/or edge orientation histograms computed at specific locations called “points of interests”) for each of the tags, then you can basically “convert” an image into a set of tags and query them. But again I am not an expert in this field and I can’t tell you much more.
You also researched hand gesture recognition. What can this be used for?
Yes, but not actively these days. I am interested in vision-based hand gesture recognition for multimodal interaction applications. The main idea is that we want to interact with a computer or a graphical user interface (such as a large screen on the wall :-)) without any devices... neither mouse, keyboard nor Wii-remote :-) We can only use audio/visual sensors to recognize speech for vocal commands or gestures for visual commands: pointing at the screen to zoom on a map, moving your hand left/right to move forward/backward in PowerPoint slides, or when playing games, or manipulating virtual 3D objects.
I wonder, have you ever pondered applying at Google Zurich?
No.
Where do you think the future of image recognition is going? For image search engines, it seems it can be an incredibly interesting field...
Yes, I think that it has a huge potential for image search engines also because it is a way to collect a lot of meta-data (tags) to improve image classification algorithms.
I also think that image recognition has a potential at home. Our personal photo/ video collections are growing as fast as the size of hard drives, and in few years we will have a Petabyte at home. And thanks to all recording devices we have (mobile phones, digital camera, handy-cam) we will be able to record our life! Then, how are we going to search in this data? Even today how can you find a picture taken 2 or 3 years ago? I don’t know when it was exactly, I don’t know where it was exactly. But what people remember is who was in the picture :-) and sometimes objects in a scene or even their color. At least this is something I remember very well. Then, automatic image recognition techniques will index our photo/ video collections and help us to retrieve information more easily.
Some of the web programmers following along might be interested to try out face recognition in their own software. Is there any e.g. PHP or Python source code to download? And which link would you suggest for people new to the subject to find out more?
Again you mean face detection or recognition? In both cases, there is no PHP or Python source code as everything is developed in C/C++ under our open source machine vision library. Unfortunately, our recent developments and best algorithms are not yet provided in the public release. BUT soon we will provide our face detection technology as a library + a C API + examples under a free but limited (in time) evaluation license. This will be available in a couple of weeks at www.ideark.ch/faceonit. Everybody will be able to test it and, if happy with it, to buy it.
Cool.
We also plan to do the same thing with the face recognition technology we already used in Banana, but this will be only if we have a lot of requests for this. However, if programmers can’t wait for this face recognition lib, they can use Torchvision, our machine vision library that already provides all the source code for all required modules to implement several face recognition algorithms. For more details about experiments and algorithms I have some labs on my web page. Anyway, anybody interested can contact me.
>> More posts
Advertisement
This site unofficially covers Google™ and more with some rights reserved. Join our forum!